
PandioML
Connect to data, feed it into a pipeline, train a model, and deploy to production with a single open source Python library!

pip install pandioml
Copy and paste the above to install
Orders Of Magnitude More Efficient
PandioML handles resources such as memory, cpu, disk more efficiently resulting in more efficient use of resources.
General Purpose
Regressions, classifications, unsupervised learning, concept drift, metrics and more are available with PandioML.
Adaptive Learning
Adaptive methods are specifically designed to address concept drift in a fast moving environment.
Not Just For Real-time
Process a single observation, a mini-batch of observations, or a full batch with PandioML.
See PandioML In Action
See how PandioML works with the Pandio.com platform
See how PandioML can work to detect credit card fraud
PandioML Provides Three Things
Access
Feed data from any source into a pipeline at any scale.
Automate
Enable data movement seamlessly. Streaming, queuing and pub-sub with unmatched throughput, latency, and durability.
Learn
Design, train, and deploy machine learning models in less than 30 minutes - all done locally. Accelerate your path to ML and democratize the process across your organization.
The 30 Minute Challenge
`pip install pandioml``pandiocli register your@gmail.com``pandiocli function generate --project_name test_function`Open `test_function/function.py` in your favorite editor, put your pipelines code in the `pipelines` method, select an algorithm to use, and go!`pandiocli test --project_folder test_function --dataset_name FormSubmissionGenerator --loops 500`
What Is Adaptive Learning?
Adaptive learning is the idea of training a model with individual or a small batch of events. As each labeled event is received, the model learns incrementally with each event.
Not Just A Python Library
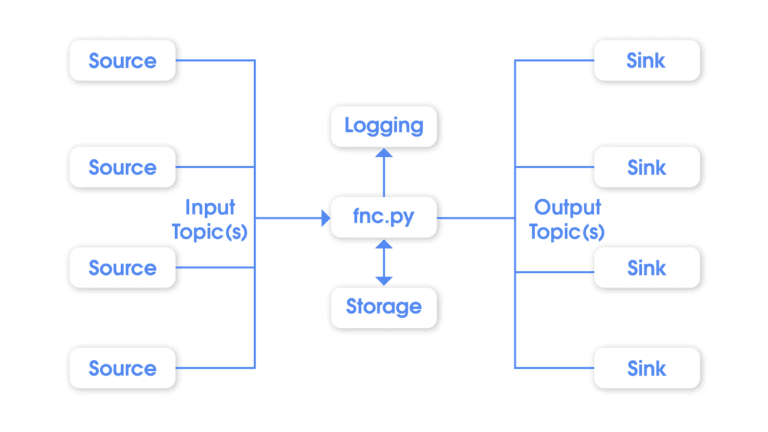
Building a pipeline with a predictive model is only half the battle. Getting it into production and scaling it so that it can provide value with its predictions is often times just as di!cult as getting a predictive model, leading to many failed initiatives.
Backed by Pandio.com, the PandioCLI interfaces with the Pandio platform allowing pipelines and models to be deployed to production with a single command. Immediately the model is available to be used as a micro-service by any authorized token from inside the Pandio.com Dashboard.
Rethinking Traditional Machine Learning
Over 90% of AI initiatives fail. That is no surprise. Lets consider the traditional journey that is taken for machine learning:
- Research how to connect to data sources.
- Connect to data sources.
- Clean data, clean data, clean data.
- Prepare data to be fed into the pipeline.
- Create training environment.
- Write training script.
- Train model.
- Throw it over the fence to software engineers.
- Create inference microservice.
- Deploy microservice.
- Scale microservice.
- Create feedback loop to continuously perform step 6-11 every hour, day, month, or quarter.
The PandioML Way Of Thinking
An end to end solution that handles most of the complexity of machine learning initiatives automatically for you.
- Connect to data sources with Pandio Datasets.
- Create your pipeline.
- Deploy pipeline to Pandio.com.
From 12 steps to 3.
Thanks to PandioCLI, incremental learning that does training and inference with the same code, PandioML, and the Pandio platform, developing and operating machine learning takes a fraction of the time and effort.
Data Science Teams Love PandioML
- Build production models quickly in days instead of months
- Use your preferred environment of Jupyter Notebook, PyCharm, etc.
- Write far less code
- Use existing data, pipelines, and models
Frequently Asked Questions
What is Pandio.com?
Pandio.com is the premier AI Orchestration platform that offers data abstraction, data movement, and data infrastructure to handle the AI workloads of tomorrow.
PandioML leverages this platform to connect the data to pipelines, run pipelines, and deploy pipelines in production.
How is this different than batch machine learning?
The difference is simply the amount of data available to process. With batch, the dataset is finite. With adaptive learning, the dataset is infinite.
Many times both methods can create the same model with the same predictive power. Adaptive learning requires less code, less operations, and less resources.
Does this only work for real-time use cases?
PandioML can be used for much more than real-time use cases.
In our experience, most production models in existence today could have been created with PandioML.
Building a model with adaptive learning is easier, more efficient, less complex, and shortens the time to market considerably.