
What Data Scientists Want to Do vs What Data Scientists Actually Do
The reality of data science in practical use today is very different from the hypothetical exercises found in academic research. Researchers propose ideal systems and then subsequently report dramatically successful outcomes which arise from ideal training datasets. But in the real world, data engineers grapple with incomplete datasets as a result of a variety of constraints, confidential medical and financial records as one example. They struggle with model selection and performance issues. In fact, an otherwise successful ML model design may fail outright because the data required violates compliance regulations. The real world of ML and data engineering is one of surprising obstacles. Fortunately, a solution is now available that dramatically reduces the complexity of building data pipelines and accelerates the launch of your data platform.
Real vs. Ideal
Enterprises keen to implement AI and ML in product development face the immediate challenge of staffing data science engineers. Finding and employing the right human capital to accurately develop an original ML project is as complex as the ML itself. Furthermore, expert domain knowledge is required for the specific ML application under development. If the ML app diagnoses pneumonia in clinical x-rays, for example, then a radiologist will be required to work with the data science team, both as advisor and to establish credibility in the outcome.
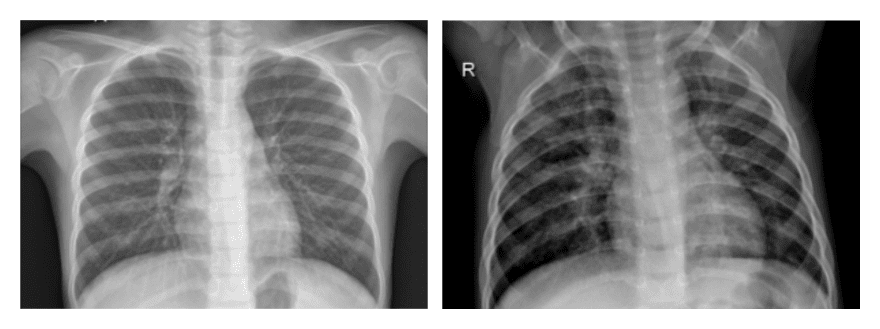
Noteworthy ML innovator and Stanford professor Andrew Ng recently cautioned about the “proof-of-concept-to-production gap,” which essentially explains why a research model which performs well on test data does not perform adequately in a real-world clinical application. The gap occurs when an idealized model and test dataset developed in a research setting fails in production because of differences in imaging protocols managed by radiologists with varying degrees of knowledge and operating equipment of varying accuracy. Herein lies the crux: what data engineers want to do vs. what they really can do? How can such a gap be resolved so that a practical ML model can succeed profitably in production and achieve actionable intelligence on an economically feasible development budget?
Emerging Solutions at PandioML
On this note, we set the stage for an alternative, that of leveraging the best existing resources as well as leveraging proven algorithms to minimize repeating known historical errors, to use known accurate systems rather than invent new ones.
PandioML now sets the stage to smoothly embed ML and AI components in your products and services. Based on a proven library of the best ML frameworks which you can implement right out of the box. Now that DL models are proven best for financial apps, for example, it is easy to implement a variety of them with PandioML including:
- Deep Multilayer Perceptron (DMLP)
- Recurrent Neural Nets (RNN)
- Long Short Term Memory (LSTM)
- Convolutional Neural Nets (CNN)
- Restricted Boltzmann Machines (RBMs)
- Deep Belief Networks (DBN)
- Autoencoder (AE)
- Deep Reinforcement Learning (DRL)
To demonstrate how using PandioML and its team of experts can zoom you to real-world production ML implementation, consider PandioML’s existing domain knowledge which will immediately benefit enterprises struggling with operationalization of ML models.For example, financial time series forecasting is usually thought of as a regression problem. However, there are also many successful use cases, particularly on trend prediction, which implement classification models to accurately solve financial forecasting problems. In finance, medicine, marketing, and manufacturing, you can leverage PandioML’s experience to reach your AI goals.
Planning an ML Project
In order to understand how different the imagined successes of AI are than the rough road actually traveled by engineers, we need to visit each milestone of ML development along the journey of a typical use case and recognize the trips and traps which are familiar to the seasoned PandioML data engineer. What are the typical steps in an ML project?
- Imagine the intended outcome and benefits of enhancing a product or service with ML.
- Understand technical challenges and write a problem statement to define the idea concretely.
- Design and build a wireframe or prototype model to answer the problem statement.
- Engage in data discovery, exploration and preprocessing, data wrangling and preparation issues, missing data, compliance issues like confidentiality. Encode categorical variables and labels. Normalize and scale the values.
- Propose and build the ML Model based on identified features to achieve forecasting.
- Build an ML Pipeline to best fit the chosen model.
- Deploy the system to production.
- Monitor, evaluate, revise and debug to improve performance.
The above outline seems like a realistic plan; is this how the development actually plays out? In theory, yes. Perhaps in idealized form it is sufficient. However, the real engineering of a data platform contains surprising complexity and unimagined pitfalls. This is where you will truly gain from partnering with PandioML.
Building on Existing Success
One pitfall in ML projects results from a good intention gone wrong: the plan to create a new and orginal ML model rather than using a proven model. Because of the highly competitive nature of the AI field, it is easily demonstrated that the best and brightest of ML models are already optimized for more than 99% of applications under development. What this means is that you can safely choose PandioML to build your data platform and use its existing proven accuracy to reach your AI goals without re-inventing incredibly complex Deep Reinforcement Learning models, for example.
The PandioML Python Library contains 78 proven ML models and everything needed to build your data platform. Furthermore, PandioML accelerates production with the PandioML Pipeline, for automating your development to production, while at the same time building Pulsar Functions for live streaming of ML models. The PandioML command line interface (CLI) puts you in total control with the ability to manually intervene and tweak PandioML API and microservices at any point in the journey.
Real-Time Event Streaming ML
Pandio’s expertise in Apache Pulsar deployments will further augment your live event streaming ML projects to achieve real-time training models which continue to optimize as more data / transactions are processed. Pulsar is ideal for streaming IoT sensor data from instruments and monitors instantly to edge-compute platforms for immediate use in ML model training and enhancement.
Steps to Success with PandioML
PandioML is essentially evolving as a hybrid AutoML platform with a team of data engineers and knowledge domain experts guiding the evolution. The familiar steps in setting up a new ML project with Pandio are as follows:
- Install PandioML & PandioCLI
- Generate a project template with PandioCLI.
- Install the library with the appropriate algorithm for your use case.
- Write Python code to define feature extraction and data labeling. the most important step. Here, the data scientist selects the algorithm and does feature extraction to train the model. PandioML is the library that supports the algorithm.
- Deploy with PandioCLI directly into Pandio’s managed Pulsar data pipeline as a microservice.
Without PandioML, a typical ML project requires dozens of meetings where the data scientist explains what the model does so that the software engineering team can translate it into production. When the data scientist hands over the project to the software engineers a new level of complexity emerges. Here, PandioML delivers smooth elegant expertise to streamline the project into production!
PandioML efficiently creates production scripts to embed the chosen model, and turn it into a microservice as needed. ML based microservices can then be implemented as infrastructure, and scaled out as microservices based on demand. With a few simple lines of code the data scientist can deploy the model directly into production via Pandio’s managed Pulsar service. No additional production scripts required, no need for any involvement from the DevOps team!
Orders of Magnitude Faster to Market
Why is live streamed learning (online machine learning) so important? Today, customer experience hinges on recommender systems’ ability to learn during the present transaction and provide predictive capabilities accordingly. This is only possible when the model’s inference is updated by including the customer’s live gestures. In other words, as training and inference happen at the same time, the customer seamlessly experiences improved suggestions in the app. The experience is improved with manifold learning.
With PandioML, a data engineer or data scientist can literally create a powerful ML model in less than 30 minutes! Easily create, manage, and deploy thousands of models. Work directly in the environment you’re comfortable with, such as Jupyter Notebook or PyCharm. PandioML handles all of the orchestration needed so that your team can focus on developing the most accurate and appropriate machine learning models to address the https://www.sandwichmedical.com business use cases appropriate to your enterprise.